Анализ существующих информационно-поисковых систем
Для того, чтобы ответы на эти вопросы оставались хоть немного удовлетворительными, разработчики поисковых машин постоянно совершенствуют алгоритмы и принципы поиска, добавляют новые функции, ускоряют работу системы. В этой статье мы обратимся к механизму работы поисковой машины Рамблер, и на примере ее устройства продемонстрируем, как достигается повышение качества и скорости поиска в условиях
постоянного роста объема информации в сети Интернет.
Полнота - это одна из основных характеристик поисковой системы, которая представляет собой отношение количества найденных по запросу документов к общему числу документов в Интернете, удовлетворяющих данному запросу.
Полнота поиска в большой мере зависит от работы системы сбора и обработки информации. В связи с постоянным ростом количества документов в сети, эта система в первую очередь должна быть масштабируемой. В Рамблере масштабируемость достигается за счет параллельного исполнения задачи произвольным количеством машин.
Сбором информации занимается робот-паук, который обходит страницы с заданными URL и скачивает их в базу данных, а затем архивирует и перекладывает в хранилище суточными порциями. Робот размещается на нескольких машинах, и каждая из них выполняет свое задание. Так, робот на одной машине может качать новые страницы, которые еще не были известны поисковой системе, а на другой - страницы, которые ранее уже были скачаны не менее месяца, но и не более года назад. Хранилище у всех машин едино. При необходимости работу можно распределить другим способом, например, разбив список URL на 10 частей и раздав их 10 машинам. Параллельная работа программы позволяет легко выдерживать дополнительную нагрузку: при увеличении количества страниц, которые нужно обойти роботу, достаточно просто распределить задачу на большее число машин.
После того, как все части информации обработаны, начинается объединение (слияние) результатов. Благодаря тому, что частичные индексные базы и основная база, к которой обращается поисковая машина, имеют одинаковый формат, процедура слияния является простой и быстрой операцией, не требующей никаких дополнительных модификаций частичных индексов. Основная база участвует в анализе как одна из частей нового индекса.
Сборка единой базы из частичных индексных баз представляет собой простой и быстрый процесс. Сопоставление страниц не требует никакой интеллектуальной обработки и происходит со скоростью чтения данных с диска. Если информации, которая генерируется на машинах-индексаторах, получается слишком много, то процедура "сливания" частей проходит в несколько этапов. Вначале частичные индексы объединяются в несколько промежуточных баз, а затем промежуточные базы и основная база предыдущей редакции пересекаются. Таких этапов может быть сколько угодно. Промежуточные базы могут сливаться в другие промежуточные базы, а уже потом объединяться окончательно. Поэтапная работа незначительно замедляет формирование единого индекса и не отражается на качестве результатов.
Точность - еще одна основная характеристика поисковой машины, которая определяется как степень соответствия найденных документов запросу пользователя. Например, если по запросу "Красная площадь" находится 150 документов, в 70 из них содержится словосочетание "Красная площадь", а в остальных просто присутствуют эти слова ("красная баба кричала на всю площадь"), то точность поиска считается равной 70/150 (~0,5). Чем точнее поиск, тем быстрее пользователь находит нужные ему документы, тем меньше "мусора" среди них встречается, тем реже найденные документы не соответствуют запросу.
Способ повышения точности поиска - это выделение устойчивых обозначений и поиск их как отдельных лексических единиц. На сегодняшний день в Рамблере реализована система распознавания таких конструкций, например C++, б/у, п/п-к. Если по запросу С++ поднимать все тексты, в которых присутствуют латинская буква С, а также знак +, то получится огромное количество документов, далеко не все из которых соответствуют запросу; кроме того, это большая работа, значительно увеличивающая время поиска.
Помимо автоматических способов увеличения точности поиска, существуют различные средства, с помощью которых пользователь сам может уточнить поиск по отдельным запросам. В первую очередь к ним относится специальный язык поискового запроса, используя который можно ограничивать количество найденных документов. Например, запрос или его часть, взятые в кавычки, обрабатываются буквально, с учетом всех стоп-слов, форм, порядка, знаков препинания. Это повышает точность поиска, но уменьшает его полноту: если часть, заключенная в кавычки, неточна, нужный документ найден не будет.
Актуальность - не менее важная характеристика поиска, которая определяется временем, проходящим с момента публикации документов в сети Интернет, до занесения их в индексную базу. Например, на следующий день после теракта в Тушино огромное количество пользователей обратились к поисковой машине Рамблер с соответствующими запросами. Объективно с момента публикации новостной информации на эту тему прошло меньше суток. Однако основные документы уже были заиндексированы и доступны для поиска, благодаря существованию "быстрой базы", которая обновляется два раза в день, а при необходимости может обновляться быстрее.
Скорость поиска тесно связана с его устойчивостью к нагрузкам. На сегодняшний день в рабочие часы к поисковой машине Рамблер приходит около 60 запросов в секунду. Такая загруженность требует сокращения времени обработки отдельного запроса. Здесь интересы пользователя и поисковой системы совпадают: посетитель хочет получить результаты как можно быстрее, а поисковая машина должна отрабатывать запрос максимально оперативно, чтобы не тормозить вычисление следующих. Схематично обработка поискового запроса изображена на рисунке 4.1
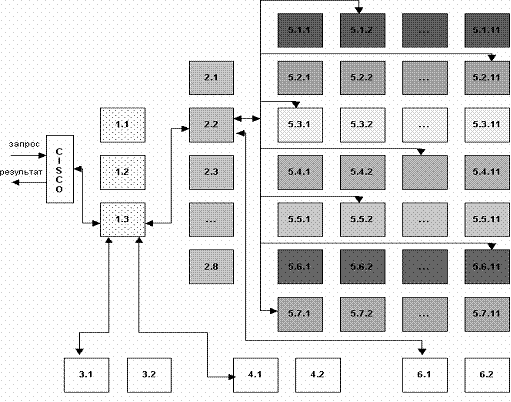
Рисунок 4.1 Схематично обработка поискового запроса
Запрос поступает в поисковую систему через маршрутизатор Cisco 6000 series. Cisco передает его наименее загруженной машине первого уровня - frontend (1.1 - 1.3, на рис. машине 1.3). Frontend, в свою очередь, отправляет запрос дальше, на один из восьми proxy-серверов, также выбирая наиболее свободный сервер (2.1 - 2.8, на рис. машине 2.2). Одновременно frontend отправляет запрос на машины, осуществляющие поиск по товарам (3.1 - 3.2, на рис. машине 3.1) и по базе Тор 100 (4.1 - 4.2, на рис. машине 4.1). На proxy проводится поиск по ссылочному индексу, и его результаты вместе с поисковым запросом передаются на машины, которые содержат основную индексную базу, - backends (5.1.х - 5.7.х, на рис. машинам 5.1.2, 5.2.11, 5.3.1 и т.д.) Та же информация отправляется на машины с "быстрой базой" (6.1 - 6.2, на рис. 6.1).
На текущий момент в поиск включено 77 backend'ов. Они сгруппированы по 11 машин, и каждая группа содержит копию одной из частей поискового индекса. Таким образом, информация о сайтах, условно входящих в красный сектор Интернета, находится на backend'ах первой группы (5.1.1 - 5.1.11 на рис), оранжевый сектор - на backend'ах второй группы (5.2.1 - 5.2.11) и т.д. Proxy-сервер выбирает наименее загруженный backend в каждой группе машин и отправляет на него поисковый запрос с результатами ссылочного поиска. На backend'ах осуществляется поиск по частям индексной базы и ранжирование с учетом результатов поиска по ссылочному индексу. При ранжировании для всех найденных документов высчитываются веса по конкретному запросу.
Другие рефераты на тему «Программирование, компьютеры и кибернетика»:
Поиск рефератов
Последние рефераты раздела
- Основные этапы объектно-ориентированного проектирования
- Основные структуры языка Java
- Основные принципы разработки графического пользовательского интерфейса
- Основы дискретной математики
- Программное обеспечение системы принятия решений адаптивного робота
- Программное обеспечение
- Проблемы сохранности информации в процессе предпринимательской деятельности