Основы дискретной математики
Этому методу требуется O (n log2n) в среднем и O(n2) в худшем случае. К счастью, если принять адекватные предосторожности, наихудший случай крайне маловероятен. Быстрый поиск не является устойчивым. Кроме того, ему требуется стек, т. е. он не является и методом сортировки на месте.
Алгоритм разбивает сортируемый массив на разделы, затем рекурсивно сортирует каждый раздел. В функции Partitio
n один из элементов массива выбирается в качестве центрального. Ключи, меньшие центрального, следует расположить слева от него, те, которые больше – справа.
int function Partition (Array A, int Lb, int Ub);
begin
select a pivot from A[Lb]… A[Ub];
reorder A[Lb]… A[Ub] such that:
all values to the left of the pivot are £ pivot
all values to the right of the pivot are ³ pivot
return pivot position;
end;
procedure QuickSort (Array A, int Lb, int Ub);
begin
if Lb < Ub then
M = Partition (A, Lb, Ub);
QuickSort (A, Lb, M – 1);
QuickSort (A, M + 1, Ub);
end;
На рисунке 1.11 (а) в качестве центрального выбран элемент 3. Индексы начинают изменяться с концов массива. Индекс i начинается слева и используется для выбора элементов, которые больше центрального, индекс j начинается справа и используется для выбора элементов, которые меньше центрального. Эти элементы меняются местами – см. рисунок 1.11 (b). Процедура QuickSort рекурсивно сортирует два подмассива, в результате получается массив, представленный на рисунке 1.11 (c).
В процессе сортировки может потребоваться передвинуть центральный элемент. Если нам повезет, выбранный элемент окажется медианой значений массива, т. е. разделит его пополам. Предположим на минутку, что это и в самом деле так. Поскольку на каждом шаге мы делим массив пополам, а функция Partition, в конце концов, просмотрит все n элементов, время работы алгоритма есть O (n log2n).
В качестве центрального функция Partition может попросту брать первый элемент (A[Lb]). Все остальные элементы массива мы сравниваем с центральным и передвигаем либо влево от него, либо вправо. Есть, однако, один случай, который безжалостно разрушает эту прекрасную простоту. Предположим, что наш массив с самого начала отсортирован. Функция Partition всегда будет получать в качестве центрального минимальный элемент и потому разделит массив наихудшим способом: в левом разделе окажется один элемент, соответственно, в правом останется Ub – Lb элементов.
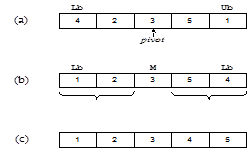
Рисунок 1.11 – Пример работы алгоритма Quicksort
Таким образом, каждый рекурсивный вызов процедуры quicksort всего лишь уменьшит длину сортируемого массива на 1. В результате для выполнения сортировки понадобится n рекурсивных вызовов, что приводит к времени работы алгоритма порядка O(n2). Один из способов побороть эту проблему – случайно выбирать центральный элемент. Это сделает наихудший случай чрезвычайно маловероятным.
Сортировка с помощью прямого выбора
При сортировке этим методом выбирается наименьший элемент массива и меняется местами с первым. Затем выбирается наименьший среди оставшихся n – 1 элементов и меняется местами со вторым и т. д. до тех пор, пока не останется один самый больший элемент. Основной фрагмент программы может выглядеть так [11]:
for i:=l to n‑1 do
begin
k: =i;
x:=a[i];
for j:=i+1 to n do
if a[j]<x then begin k:=j; x:=a[k] end;a[k]:=a[i]; a[i]: =xend;
k – величина, хранящая индекс элемента, участвующего в операции обмена.
Сортировка файлов
Главная особенность методов сортировки последовательных файлов в том, что при их обработке в каждый момент непосредственно доступна одна компонента (на которую указывает указатель). Чаще процесс сортировки протекает не в оперативной памяти, как в случае с массивами, а с элементами на внешних носителях («винчестере», дискете и т. п.).
Понять особенности сортировки последовательных файлов на внешних носителях позволит следующий пример [9].
Предположим, что нам необходимо упорядочить содержимое файла с последовательным доступом по какому-либо ключу. Для простоты изучения и анализа сортировки условимся, что файл формируем мы сами, используя, как и в предыдущем разделе, некоторый массив данных. Его же будем использовать и для просмотра содержимого файла после сортировки. В предлагаемом ниже алгоритме необходимо сформировать вспомогательный файл, который позволит осуществить следующую процедуру сортировки. Сначала выбираем из исходного файла первый элемент в качестве ведущего, затем извлекаем второй и сравниваем с ведущим. Если он оказался меньше, чем ведущий, то помещаем его во вспомогательный файл, в противном случае во вспомогательный файл помещается ведущий элемент, а его замещает второй элемент исходного файла. Первый проход заканчивается, когда аналогичная процедура коснется всех последовательных элементов исходного файла. Ведущий элемент заносится во вспомогательный файл последним. Теперь необходимо поменять местами исходный и вспомогательный файлы. После nil проходов в исходном файле данные будут размещены в упорядоченном виде.
program sortirovka_faila_1;
{сортировка последовательного файла}
const n=8; type item= integer;
var a: array [1 n] of item;
i, k: integer; x, y: item;
fl, f2: text; {file of item};
begin
{задание искомого массива}
for i:=1 to N do begin write ('введи элемент а ['i, '] = ');
readln (a[i]);
end;
writeln; assign (fl, 'datl.dat'); rewrite(fl);
assign (f2, 'dat2.dat'); rewrite(f2);
{формирование последовательного файла}
for i:=1 to N do begin writeln (fl, a[i]);
end;
{алгоритм сортировки с использованием вспомогательного файла}
for k:=1 to (n div 2) do
begin {извлечение из исходного файла и запись во вспомогательный}
reset(fl); readln (fl, x);
for i:=2 to n do begin readln (fl, y);
if x>y then writeln (f2, y) else begin writeln (f2, x); x:=y;
end;
end;
writeln (f2, x);
{извлечение из вспомогательного файла и запись в исходный}
rewrite(fl); reset(f2); readln (f2, x);
for i:=2 to n do begin readln (f2, y);
if x>y then writeln (fl, y) else begin writeln (fl, x); x:=y;
end;
end;
writeln (fl, x); rewrite(f2); end;
(вывод результата)
reset(fl);
for i:=1 to N do readln (fl, a[i]);
for i:=1 to N do begin write (a[i], ' ');
end;
close(fl); close(f2); readln;
end.
По сути можно в программе обойтись без массива а [1 n]. В качестве упражнения попытайтесь создать программу, в которой не используются массивы.
Многие методы сортировки последовательных файлов основаны на процедуре слияния, означающей объединение двух (или более) последовательностей в одну, упорядоченную с помощью повторяющегося выбора элементов (доступных в данный момент). В дальнейшем (чтобы не осуществлять многократного обращения к внешней памяти), будем рассматривать вместо файла массив данных, обращение к которому можно осуществлять строго последовательно. В этом смысле массив представляется как последовательность элементов, имеющая два конца, с которых можно считывать данные. При слиянии можно брать элементы с двух концов массива, что эквивалентно считыванию элементов из двух входных файлов.
Другие рефераты на тему «Программирование, компьютеры и кибернетика»:
- Моделирование логнормального распределения
- On-line распознавание рукописных символов
- Разработка системы автоматизированного электронного документооборота для предприятия
- 2683 Перспективы развития вычислительных систем. Квантовые компьютеры и нейровычислители
- Моделирование и исследование обрабатывающего участка цеха, производящего обработку деталей
Поиск рефератов
Последние рефераты раздела
- Основные этапы объектно-ориентированного проектирования
- Основные структуры языка Java
- Основные принципы разработки графического пользовательского интерфейса
- Основы дискретной математики
- Программное обеспечение системы принятия решений адаптивного робота
- Программное обеспечение
- Проблемы сохранности информации в процессе предпринимательской деятельности