Пакет программ Майкрософт, как эффективное средство эконометрического анализа
В регрессионной статистике указываются множественный коэффициент корреляции (Множественный R) и детерминации (R-квадрат) между Y и массивом факторных признаков (что совпадает с полученными ранее значениями в корреляционном анализе)
Средняя часть таблицы (Дисперсионный анализ) необходима для проверки значимости уравнения регрессии.
Нижняя часть таблицы – точ
ечные оценки bi генеральных коэффициентов регрессии вi, проверка их значимости и интервальная оценка.
Оценка вектора коэффициентов b (столбец Коэффициенты):
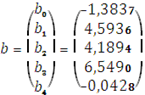
Тогда оценка уравнения регрессии имеет вид:
![]()
Необходимо проверить значимость уравнения регрессии и полученных коэффициентов регрессии.
Проверим на уровне б=0,05 значимость уравнения регрессии, т.е. гипотезу H0: в1=в2=в3=…=вk=0. Для этого рассчитывается наблюдаемое значение F-статистики:
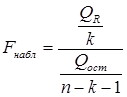
Excel выдаёт это в результатах дисперсионного анализа:
QR=527,4296; Qост=1109,8673 =>
В столбце F указывается значение Fнабл.
По таблицам F-распределения или с помощью встроенной статистической функции FРАСПОБР для уровня значимости б=0,05 и числа степеней свободы числителя н1=k=4 и знаменателя н2=n-k-1=45 находим критическое значение F-статистики, равное
Fкр = 2,578739184
Так как наблюдаемое значение F-статистики превосходит ее критическое значение 8,1957 > 2,7587, то гипотеза о равенстве вектора коэффициентов отвергается с вероятностью ошибки, равной 0,05. Следовательно, хотя бы один элемент вектора в=(в1,в2,в3,в4)T значимо отличается от нуля.
Проверим значимость отдельных коэффициентов уравнения регрессии, т.е. гипотезу ![]() .
.
Проверку значимости регрессионных коэффициентов проводят на основе t-статистики  для уровня значимости
для уровня значимости ![]() .
.
Наблюдаемые значения t-статистик указаны в таблице результатов в столбце t-статистика.
|
Коэффициенты (bi) |
t-статистика (tнабл) | ||
|
Y-пересечение |
b0=-1,3837 |
-0,0872 | |
|
Переменная X5 |
b1= 4,5936 |
0,2630 | |
|
Переменная X7 |
b2 = 4,1894 |
0,7300 | |
|
Переменная X10 |
b3= 6,5490 |
3,7658 | |
|
Переменная X15 |
b4 =-0,0428 |
-1,6629 |
Их необходимо сравнить с критическим значением tкр, найденным для уровня значимости б=0,05 и числа степеней свободы н=n – k - 1.
Для этого используем встроенную статистическую функцию Excel СТЬЮДРАСПОБР, введя в предложенное меню вероятность б=0,05 и число степеней свободы н= n–k-1=50-4-1=45. (Можно найти значения tкр по таблицам математической статистики.
Получаем tкр= 2,014103359.
Для ![]()
![]() наблюдаемое значение t-статистики меньше критического по модулю 2,0141>|-0,0872|, 2,0141>|0,2630|, 2,0141>|0,7300|, 2,0141>|-1,6629|.
наблюдаемое значение t-статистики меньше критического по модулю 2,0141>|-0,0872|, 2,0141>|0,2630|, 2,0141>|0,7300|, 2,0141>|-1,6629|.
Следовательно, гипотеза о равенстве нулю этих коэффициентов не отвергается с вероятностью ошибки, равной 0,05, т.е. соответствующие коэффициенты незначимы.
Для ![]() наблюдаемое значение t-статистики больше критического значения по модулю |3,7658|>2,0141, следовательно, гипотеза H0 отвергается, т.е.
наблюдаемое значение t-статистики больше критического значения по модулю |3,7658|>2,0141, следовательно, гипотеза H0 отвергается, т.е. ![]() - значим.
- значим.
Значимость регрессионных коэффициентов проверяют и следующие столбцы результирующей таблицы:
Столбец p-значение показывает значимость параметров модели граничным 5%-ым уровнем, т.е. если p≤0,05, то соответствующий коэффициент считается значимым, если p>0,05, то незначимым.
И последние столбцы – нижние 95% и верхние 95% и нижние 98% и верхние 98% - это интервальные оценки регрессионных коэффициентов с заданными уровнями надёжности для г=0,95 (выдаётся всегда) и г=0,98 (выдаётся при установке соответствующей дополнительной надёжности).
Если нижние и верхние границы имеют одинаковый знак (ноль не входит в доверительный интервал), то соответствующий коэффициент регрессии считается значимым, в противном случае – незначимым
Как видно из таблицы, для коэффициента в3 p-значение p=0,0005<0,05 и доверительные интервалы не включают ноль, т.е. по всем проверочным критериям этот коэффициент является значимым.
Согласно алгоритму пошагового регрессионного анализа с исключением незначимых регрессоров, на следующем этапе необходимо исключить из рассмотрения переменную, имеющую незначимый коэффициент регрессии.
В случае, когда при оценке регрессии выявлено несколько незначимых коэффициентов, первым из уравнения регрессии исключается регрессор, для которого t-статистика (![]() ) минимальна по модулю. По этому принципу на следующем этапе необходимо исключить переменную Х5 , имеющую незначимый коэффициент регрессии в2
) минимальна по модулю. По этому принципу на следующем этапе необходимо исключить переменную Х5 , имеющую незначимый коэффициент регрессии в2
II ЭТАП РЕГРЕССИОННОГО АНАЛИЗА.
В модель включены факторные признаки X7, X10, X15, исключён X5.
|
ВЫВОД ИТОГОВ | ||||||||||||||||||
|
Регрессионная статистика | ||||||||||||||||||
|
Множественный R |
0,56665 | |||||||||||||||||
|
R-квадрат |
0,321093 | |||||||||||||||||
|
Нормированный R-квадрат |
0,276816 | |||||||||||||||||
|
Стандартная ошибка |
4,915753 | |||||||||||||||||
|
Наблюдения |
50 | |||||||||||||||||
|
Дисперсионный анализ | ||||||||||||||||||
|
df (число степеней свободы н) |
SS (сумма квадратов отклонений Q) |
MS (средний квадрат MS=SS/н) |
F (Fнабл= MSR/MSост) |
Значимость F | ||||||||||||||
|
Регрессия |
3 |
525,7241 |
175,2414 |
7,251979 |
0,00044 | |||||||||||||
|
Остаток |
46 |
1111,573 |
24,16463 | |||||||||||||||
|
Итого |
49 |
1637,297 | ||||||||||||||||
|
Коэффи-циенты (bi) |
Стандартная ошибка (Ŝbi) |
t-ста-тистика (tнабл) |
P-Значение |
Нижние 95% (вimin) |
Верхние 95% (вimax) |
Нижние 98% (вimin) |
Верхние 98% (вimax) | |||||||||||
|
Y-пересечение |
1,94084 |
9,492634 |
0,204457 |
0,838898 |
-17,1668 |
21,04852 |
-20,9382 |
24,81987 | ||||||||||
|
Переменная X7 |
4,502469 |
5,556948 |
0,810241 |
0,421973 |
-6,68309 |
15,68803 |
-8,89082 |
17,89576 | ||||||||||
|
Переменная X10 |
6,569053 |
1,719766 |
3,819738 |
0,000399 |
3,107345 |
10,03076 |
2,424095 |
10,71401 | ||||||||||
|
Переменная X15 |
-0,0465 |
0,021196 |
-2,19389 |
0,033333 |
-0,08917 |
-0,00384 |
-0,09759 |
0,004584 | ||||||||||
Другие рефераты на тему «Экономико-математическое моделирование»:
Поиск рефератов
Последние рефераты раздела
- Выборочные исследования в эконометрике
- Временные характеристики и функция времени. Графическое представление частотных характеристик
- Автоматизированный априорный анализ статистической совокупности в среде MS Excel
- Биматричные игры. Поиск равновесных ситуаций
- Анализ рядов распределения
- Анализ состояния финансовых рынков на основе методов нелинейной динамики
- Безработица - основные определения и измерение. Потоки, запасы, утечки, инъекции в модели